
Hi, I'm Karim! I am a first year CS PhD student at UC Berkeley, advised by Stuart Russell. My work is partially supported by the Cooperative AI PhD Fellowship.
Research Interests I am broadly interested in Reinforcement Learning, Cooperative AI, and AI Safety. My research style is a mix of both theory and practice, with the goal of designing methods which are both well-founded and that have the potential to scale empirically. Recently, I have been mostly excited about designing better ways to do inverse RL and preference learning, designing protocols with the right incentives in human-AI collaboration, and in more foundational topics in RL theory and game theory.
Before starting my PhD, I spent time at the Center for Human-Compatible AI and at the Krueger AI Safety Lab, University of Cambridge, where I was fortunate to be supervised by Michael Dennis, Micah Carroll and David Krueger.
I completed my MSc in AI at the University of Amsterdam in 2025. Before my MSc , I graduated with a BSc in Mathematics and Computer Science at Bocconi University. I was fortunate to be advised by Marek Eliáš, working on online learning. During my BSc, I spent the Spring '23 semester at Georgia Tech, supported with a full-ride scholarship.Please reach out if you are interested in my research, you want to have a quick chat, or anything else! You can e-mail me at karimabdel at berkeley dot edu.
News
Selected Publications (view all )
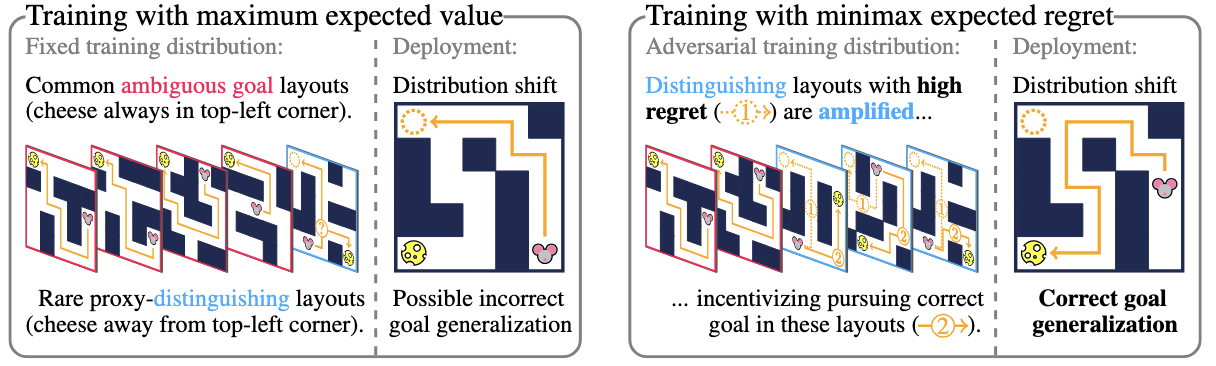
Mitigating Goal Misgeneralization via Minimax Regret
Reinforcement Learning Conference (RLC) 2025
Karim Abdel Sadek*, Matthew Farrugia-Roberts*, Usman Anwar, Hannah Erlebach, Christian Schroeder de Witt, David Krueger, Michael Dennis (* equal contribution)
Goal misgeneralization can occur when the policy generalizes capably with respect to a 'proxy goal' whose optimal behavior correlates with the intended goal on the training distribution, but not out of distribution. We observe that if some training signal towards the intended reward function exists, it can be amplified by regret-based prioritization. We formally show that approximately optimal policies on maximal-regret levels avoid the harmful effects of goal misgeneralization, which may exist without this prioritization. Empirically, we find that current regret-based Unsupervised Environment Design (UED) methods can mitigate the effects of goal misgeneralizatio.
Mitigating Goal Misgeneralization via Minimax Regret
Reinforcement Learning Conference (RLC) 2025
Karim Abdel Sadek*, Matthew Farrugia-Roberts*, Usman Anwar, Hannah Erlebach, Christian Schroeder de Witt, David Krueger, Michael Dennis (* equal contribution)
Goal misgeneralization can occur when the policy generalizes capably with respect to a 'proxy goal' whose optimal behavior correlates with the intended goal on the training distribution, but not out of distribution. We observe that if some training signal towards the intended reward function exists, it can be amplified by regret-based prioritization. We formally show that approximately optimal policies on maximal-regret levels avoid the harmful effects of goal misgeneralization, which may exist without this prioritization. Empirically, we find that current regret-based Unsupervised Environment Design (UED) methods can mitigate the effects of goal misgeneralizatio.
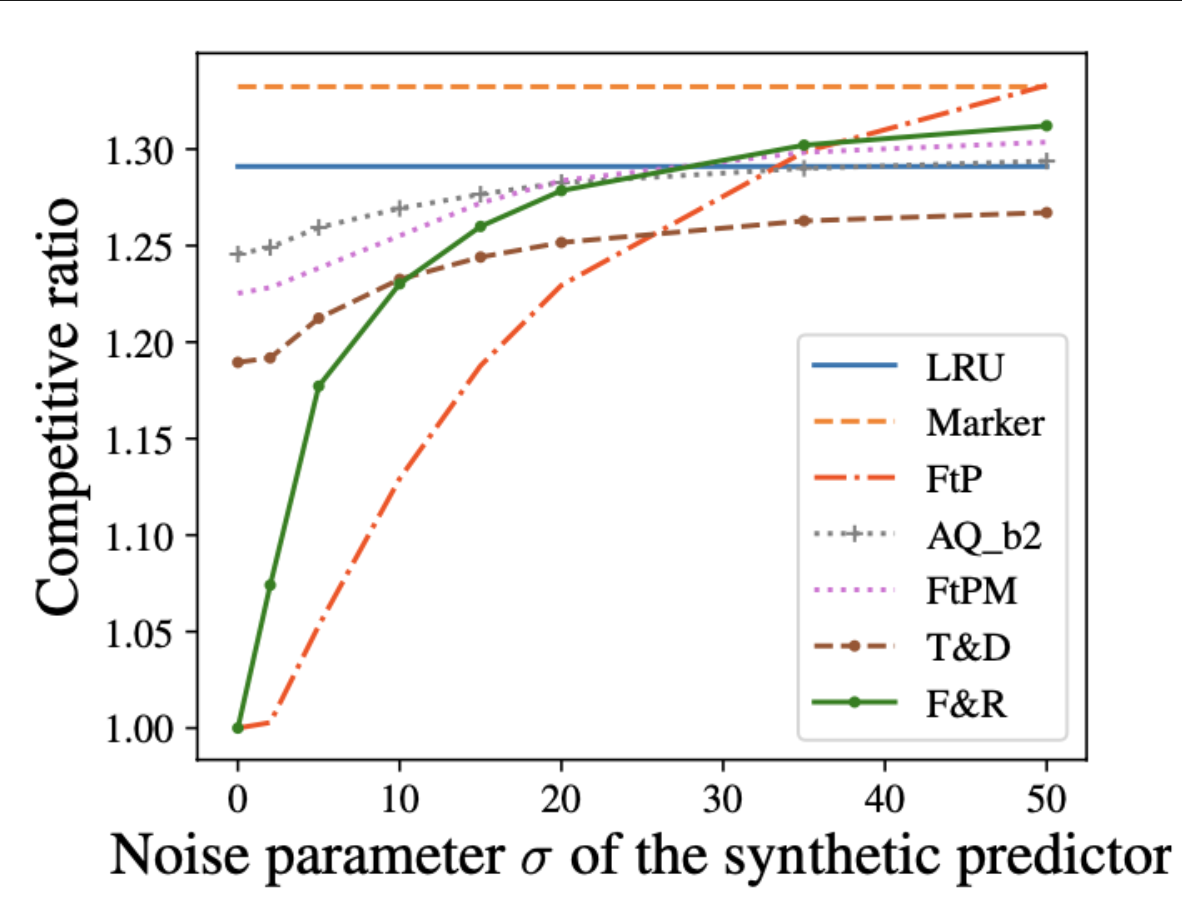
Algorithms for Caching and MTS with reduced number of predictions
International Conference on Learning Representations (ICLR) 2024
Karim Abdel Sadek, Marek Eliáš
ML-augmented algorithms utilize predictions to achieve performance beyond their worst-case bounds. We design parsimonious algorithms for caching and MTS with action predictions. Our algorithm for caching is 1-consistent, robust, and its smoothness deteriorates with decreasing number of available predictions. We propose an algorithm for general MTS whose consistency and smoothness both scale linearly with the decreasing number of predictions. Without restriction on the number of available predictions, both algorithms match the earlier guarantees achieved by Antoniadis et al. [2023].
Algorithms for Caching and MTS with reduced number of predictions
International Conference on Learning Representations (ICLR) 2024
Karim Abdel Sadek, Marek Eliáš
ML-augmented algorithms utilize predictions to achieve performance beyond their worst-case bounds. We design parsimonious algorithms for caching and MTS with action predictions. Our algorithm for caching is 1-consistent, robust, and its smoothness deteriorates with decreasing number of available predictions. We propose an algorithm for general MTS whose consistency and smoothness both scale linearly with the decreasing number of predictions. Without restriction on the number of available predictions, both algorithms match the earlier guarantees achieved by Antoniadis et al. [2023].