2025
Mitigating Goal Misgeneralization via Minimax Regret
Reinforcement Learning Conference (RLC) 2025
Karim Abdel Sadek*, Matthew Farrugia-Roberts*, Usman Anwar, Hannah Erlebach, Christian Schroeder de Witt, David Krueger, Michael Dennis (* equal contribution)
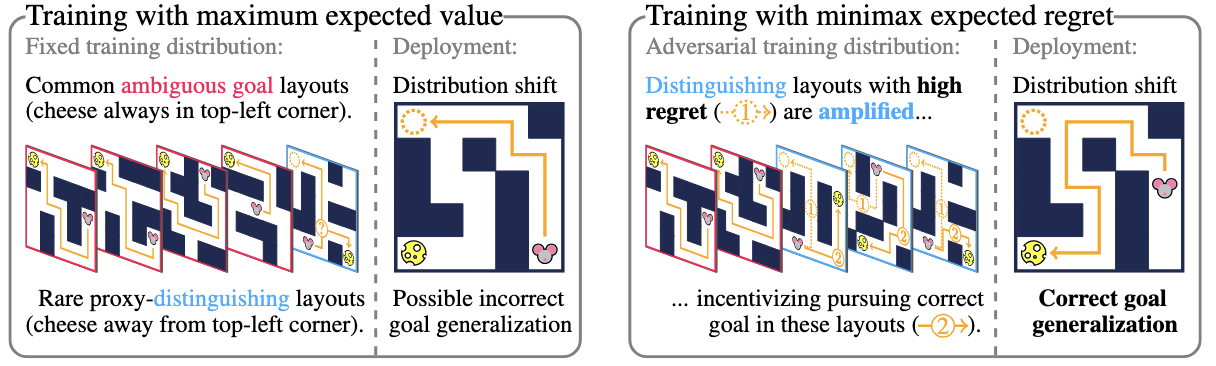
Goal misgeneralization can occur when the policy generalizes capably with respect to a 'proxy goal' whose optimal behavior correlates with the intended goal on the training distribution, but not out of distribution. We observe that if some training signal towards the intended reward function exists, it can be amplified by regret-based prioritization. We formally show that approximately optimal policies on maximal-regret levels avoid the harmful effects of goal misgeneralization, which may exist without this prioritization. Empirically, we find that current regret-based Unsupervised Environment Design (UED) methods can mitigate the effects of goal misgeneralizatio.
Mitigating Goal Misgeneralization via Minimax Regret
Reinforcement Learning Conference (RLC) 2025
Karim Abdel Sadek*, Matthew Farrugia-Roberts*, Usman Anwar, Hannah Erlebach, Christian Schroeder de Witt, David Krueger, Michael Dennis (* equal contribution)
Goal misgeneralization can occur when the policy generalizes capably with respect to a 'proxy goal' whose optimal behavior correlates with the intended goal on the training distribution, but not out of distribution. We observe that if some training signal towards the intended reward function exists, it can be amplified by regret-based prioritization. We formally show that approximately optimal policies on maximal-regret levels avoid the harmful effects of goal misgeneralization, which may exist without this prioritization. Empirically, we find that current regret-based Unsupervised Environment Design (UED) methods can mitigate the effects of goal misgeneralizatio.
2024
Dynamic Vocabulary Pruning in Early-Exit LLMs
ENLSP Workshop, NeurIPS 2024
Jort Vincenti*, Karim Abdel Sadek*, Joan Velja*, Matteo Nulli*, Metod Jazbec# (* equal contribution, # corresponding author)
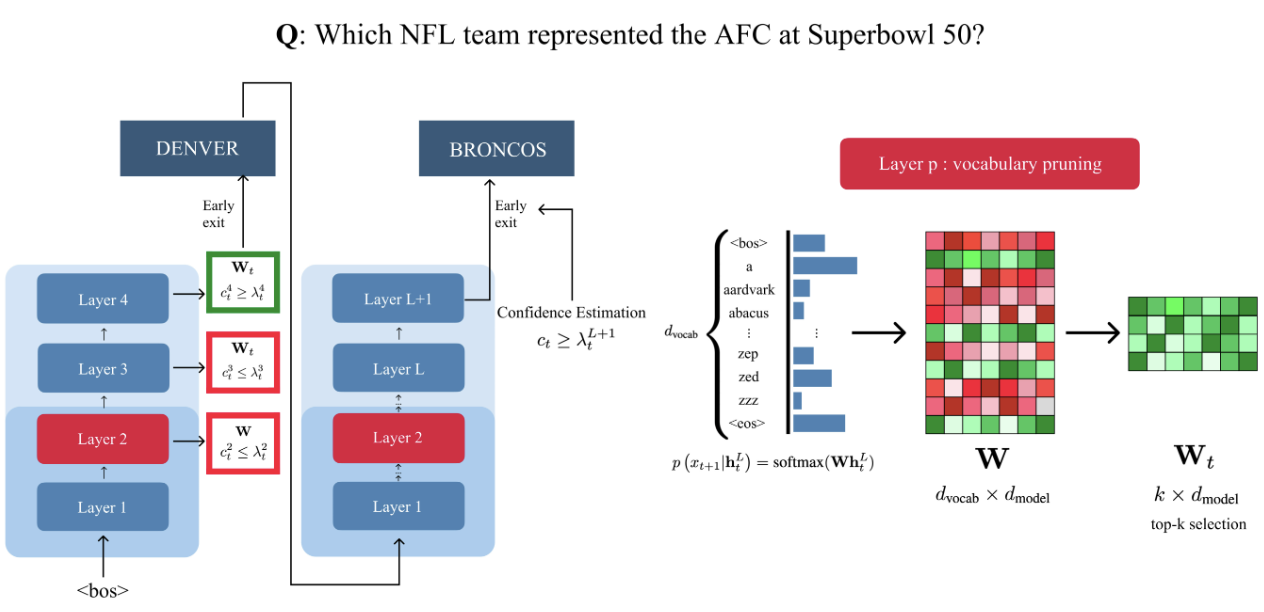
Increasing the size of large language models (LLMs) has been shown to lead to better performance. However, this comes at the cost of slower and more expensive inference. To address this, we propose dynamically pruning the vocabulary at test time for each token. Specifically, the vocabulary is pruned at one of the initial layers, and the smaller vocabulary is then used throughout the rest of the forward pass. Our experiments demonstrate that such post-hoc dynamic vocabulary pruning improves the efficiency of confidence estimation in early-exit LLMs while maintaining competitive performance.
Dynamic Vocabulary Pruning in Early-Exit LLMs
ENLSP Workshop, NeurIPS 2024
Jort Vincenti*, Karim Abdel Sadek*, Joan Velja*, Matteo Nulli*, Metod Jazbec# (* equal contribution, # corresponding author)
Increasing the size of large language models (LLMs) has been shown to lead to better performance. However, this comes at the cost of slower and more expensive inference. To address this, we propose dynamically pruning the vocabulary at test time for each token. Specifically, the vocabulary is pruned at one of the initial layers, and the smaller vocabulary is then used throughout the rest of the forward pass. Our experiments demonstrate that such post-hoc dynamic vocabulary pruning improves the efficiency of confidence estimation in early-exit LLMs while maintaining competitive performance.
Algorithms for Caching and MTS with reduced number of predictions
International Conference on Learning Representations (ICLR) 2024
Karim Abdel Sadek, Marek Eliáš
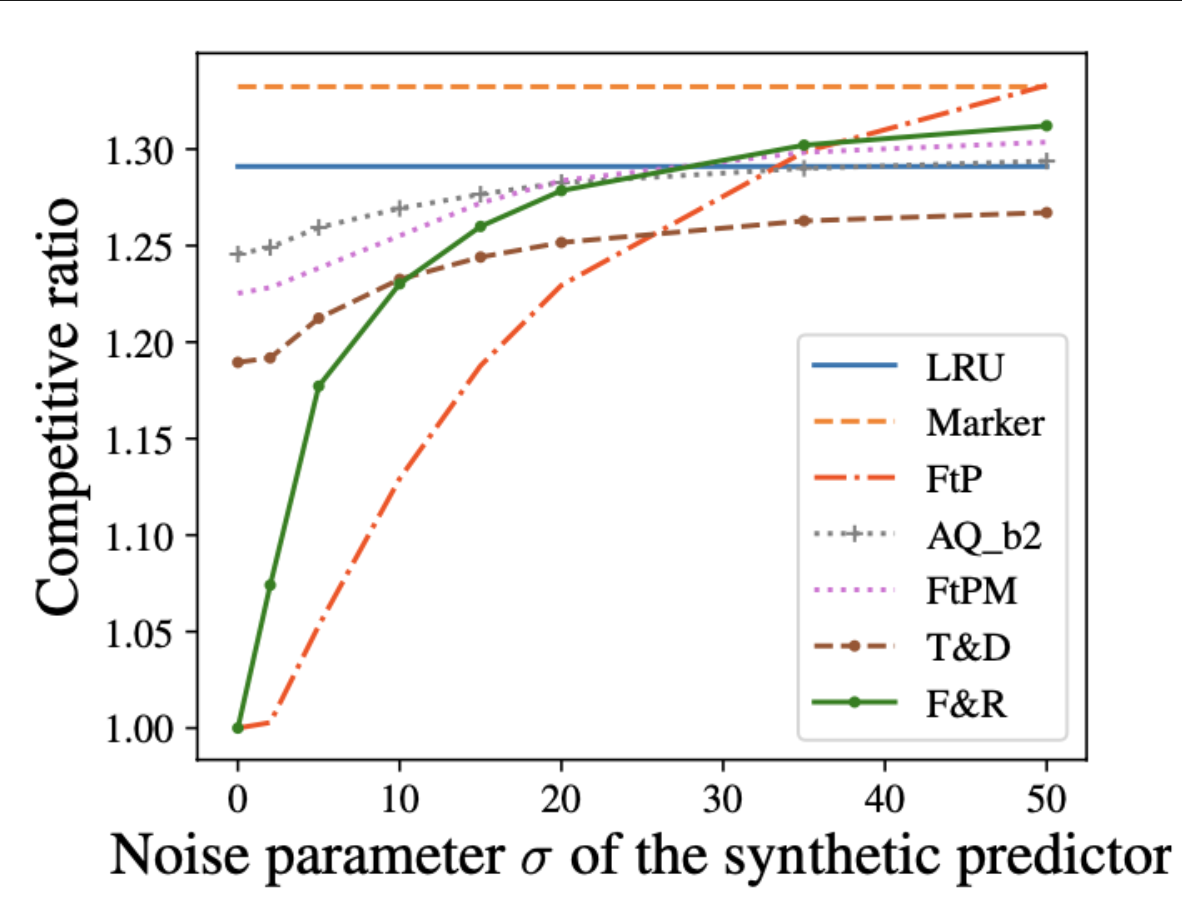
ML-augmented algorithms utilize predictions to achieve performance beyond their worst-case bounds. We design parsimonious algorithms for caching and MTS with action predictions. Our algorithm for caching is 1-consistent, robust, and its smoothness deteriorates with decreasing number of available predictions. We propose an algorithm for general MTS whose consistency and smoothness both scale linearly with the decreasing number of predictions. Without restriction on the number of available predictions, both algorithms match the earlier guarantees achieved by Antoniadis et al. [2023].
Algorithms for Caching and MTS with reduced number of predictions
International Conference on Learning Representations (ICLR) 2024
Karim Abdel Sadek, Marek Eliáš
ML-augmented algorithms utilize predictions to achieve performance beyond their worst-case bounds. We design parsimonious algorithms for caching and MTS with action predictions. Our algorithm for caching is 1-consistent, robust, and its smoothness deteriorates with decreasing number of available predictions. We propose an algorithm for general MTS whose consistency and smoothness both scale linearly with the decreasing number of predictions. Without restriction on the number of available predictions, both algorithms match the earlier guarantees achieved by Antoniadis et al. [2023].
'Explaining RL Decisions with Trajectories': A Reproducibility Study
Transactions on Machine Learning Research (TMLR) 2024
Karim Abdel Sadek, Matteo Nulli, Joan Velja, Jort Vincenti
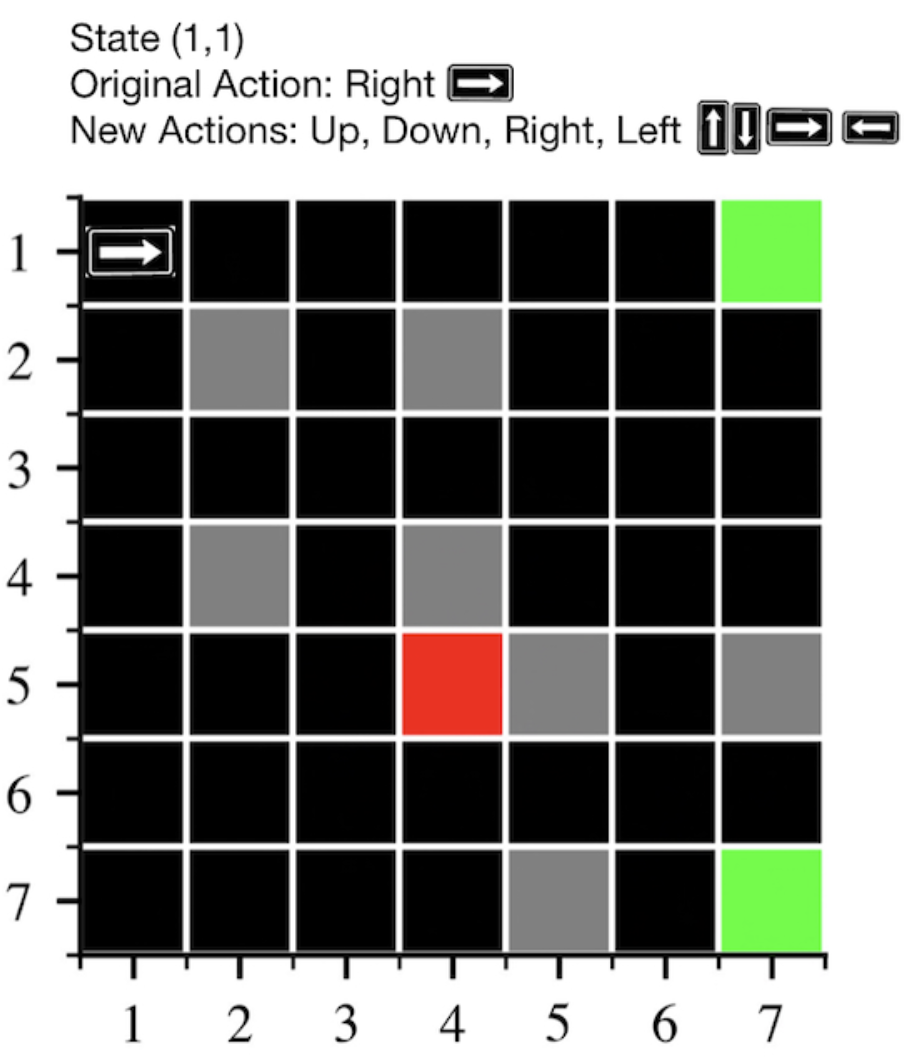
This work investigates the reproducibility of the paper 'Explaining RL decisions with trajectories'. We verify the main claims from the paper, and extend their results. We were able to reproduce the results only partially. We recognise the novelty of the work from the authors and hope that our work paves the way for clearer and more transparent approaches.
'Explaining RL Decisions with Trajectories': A Reproducibility Study
Transactions on Machine Learning Research (TMLR) 2024
Karim Abdel Sadek, Matteo Nulli, Joan Velja, Jort Vincenti
This work investigates the reproducibility of the paper 'Explaining RL decisions with trajectories'. We verify the main claims from the paper, and extend their results. We were able to reproduce the results only partially. We recognise the novelty of the work from the authors and hope that our work paves the way for clearer and more transparent approaches.